
Are you a business owner with a website with multiple pages and many new URLs that are auto-generated every day? If this is your website, then Google might not crawl all of these pages effectively. The most important point is to prioritize what and when and how much to crawl.
In simple terms, according to Google, a” define crawl budget as the number of URLs Googlebot can and wants to crawl.” Both the crawl rate limit and the crawl demand make up the crawl budget. While crawling a website, the number of requests made by Googlebot per second is considered the crawl rate. The crawl demand is where Googlebot determines how popular new and old pages are and the prevention of URLs becoming stale in the index. The more pages are crawled by search engine bots; the more will be indexed for search results.
Most often than not, the crawl budget is overlooked when optimizing a website. Many do not realize that it is a significant SEO factor that can bring traffic to your website.
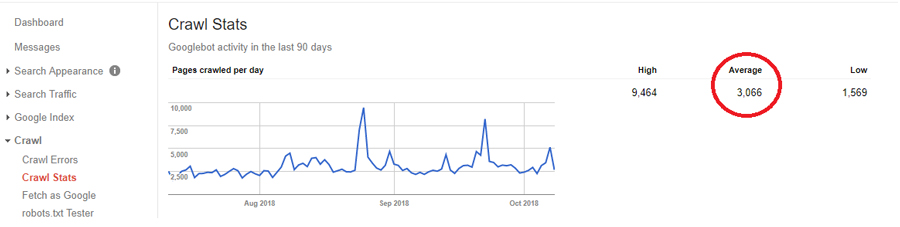
The above screenshot is from Google search console (Google Webmaster Tools). It tells us that Google crawls 3,066 pages per day for the verified website. From that, we can figure it out that the monthly crawl budget for this site is ~3,066*30=~91,980.
Fact check:
A healthy crawl rate will help your websites get indexed effectively and quickly. But don’t jump to the conclusion that a higher crawl rate will help improve your organic ranking.
Irrespective of the source of the content, duplicate content can negatively impact your SEO efforts, and wastes crawl budget to a significant level. Duplicate content can happen in many ways.
Internal content duplication
Internal content duplication may occur when different URLs point to a single page.
Duplication with URL parameters
Base URLs added with parameters would create N-number of duplicate pages
E-commerce duplication
Sorting and filter options will create unintentional internal duplication
The similar problem occurs with websites that offer calendars to save certain events/webinars etc.
Pages created via tags, and authors sections create thin / low-value content. This occurs mostly within the blog post section. These pages are planned for users and search engine bots to find relevant pages and improve internal navigation.
If a website has a huge number of 404 and soft 404 errors, these need to be fixed. Since Googlebot tend to revisit the pages to validate if they are still non-indexable. Keeping an eye on pages that return 404 status code is key to keep things on track.
If your site has an unreasonable number of redirect chains, bots will stop following the directions, and the destination URL may not get the bots’ attention. Each redirection is a waste of one unit in your allocated crawl budget.
Robots.txt file instructs bots what to crawl and what not to crawl. Thus, not using it properly might consume a considerable amount of crawl budget units.
An XML sitemap is the most important section of your website which helps proper crawling and indexing. Knockout the errors in the XML sitemaps (404s, non-canonical, redirected URLs, URLs blocked by robots and meta tag) and validate it frequently.
Bots will find it difficult to find fresh content and pages if the site structure is not developed properly. Having proper silo structure and internal linking structure will help improve the crawling and indexing.
The faster the page loads and the response time the better for your users and search bots. The faster a web page loads not only keeps the user on the website, but it also ensures web crawlers are keen to re-crawl your website. So, if your website load time is slow, it negatively affects the crawling. Google’s page speed insights can be the first place for anyone to work around the improvement.
To have a more detailed breakdown of the crawl stats by individual pages, we need to analyze the spiders’ footprints in the server logs. Often raw log files are hard to read and analyze, to help make the job easier, tools available in the market.
Crawl optimization will help you get rid of inactive pages that are not useful from your website and help you build more useful and active pages. This will gradually and positively impact the indexation and internal popularity of the website and mainly for the most focused pages for your business.
In short, Crawl budget helps you bring positive ROI with much fewer pages but are very active and important pages.
Crawl budget is not as popular and talked about when referring to ‘quality content’ or ‘authoritative links.’ However, it is very much an important factor for larger e-commerce sites and content portals. When you spend time analyzing your server logs and optimize your crawl budget, it not only gives a cleaner site but will improve your site’s performance in organic search.
Are you a business owner and still not sure where to start crawl budget optimization for your website? Let our experts do it for you. Let’s talk about it!
